brew install llama.cpp # llama.cpp 설치
llama-server --hf-repo microsoft/Phi-3-mini-4k-instruct-gguf --hf-file Phi-3-mini-4k-instruct-q4.gguf
서버를 설치하고 실행한 다음에 브라우저에서 localhost:8080으로 접속하면 다음과
같은 화면이 나옵니다.
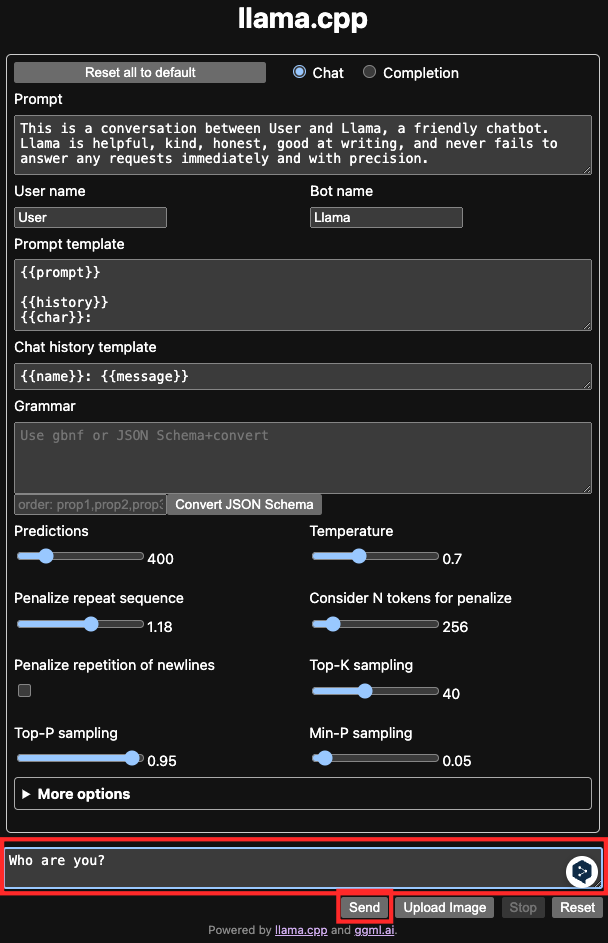
맨 아래에 프롬프트를 입력하고 엔터 혹은 send버튼을 클릭합니다.
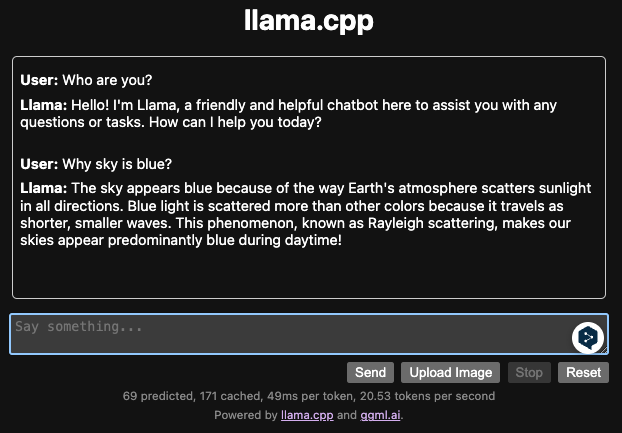
그러면 응답이 오는 것을 확인할 수 있습니다. 채팅창에 입력을 하여 계속 사용할 수 있습니다.
HTTP 요청으로도 프롬프트를 입력할 수 있습니다.
$ curl -X POST http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "phi3",
"messages": [
{ "role": "user", "content": "Why is the sky blue?" }
]
}'
# 응답
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": " The sky appears blue to the human eye because of a phenomenon called Rayleigh scattering. When sunlight reaches Earth's atmosphere, it is made up of different colors of light, which correspond to different
# ... 생략
pip install huggingface_hub
huggingface-cli login
huggingface-cli download microsoft/Phi-3-mini-4k-instruct-gguf --local-dir phi3
llama-server --model ./phi3/Phi-3-mini-4k-instruct-q4.gguf
# 모델 파일 다운로드
huggingface-cli JetBrains/CodeLlama-7B-Kexer --local-dir CodeLlama-7B-Kexer
# quantize
docker run --rm -v /path/to/model/CodeLlama-7B-Kexer:/repo ollama/quantize -q q4_0 /repo
# 라마 서버 실행
llama-server --model /path/to/model/CodeLlama-7B-Kexer/q4_0.bin
git clone git@github.com:ggerganov/llama.cpp.git
cd llama.cpp
pip install -r requirements.txt
python convert-hf-to-gguf.py /path/to/model/CodeLlama-7B-Kexer
make -C llm/llama.cpp quantize
./quantize /path/to/model/CodeLlama-7B-Kexer/ggml-model-f16.gguf /path/to/model/CodeLlama-7B-Kexer/ggml-model-Q4_K_M.gguf Q4_K_M
자바스크립트로 직접 만들면서 배우는 - 자료구조와 알고리즘 강의 바로 가기
실습으로 마스터하는 OAuth 2.0: 기본부터 보안 위험까지 - OAuth 2.0 강의 바로 가기
기계인간 이종립, 소프트웨어 개발의 지혜 - Git 강의 바로 가기
코드숨에서 매주 스터디를 진행하고 있습니다. 메일을 등록하시면 새로운 스터디가 시작될 때 알려드릴게요!
